Neural Network Playground
Tensorflow Playground is an interactive tool for learning neural networks (more specifically, multi-layer-perceptron11A perceptron model typically uses a heaviside step function as its activation. Since we use a sigmoid (or other differentiable nonlinearity), our representation not exactly a perceptron model, but that is what we call it networks). A customized version of Tensorflow Playground for CS6316/4501 HW6 is available at http://www.cs.virginia.edu/~wx4ed/playground/playground_uva.html.
First, we will get familiar with the interface of Tensorflow Playground. Let’s get to it!
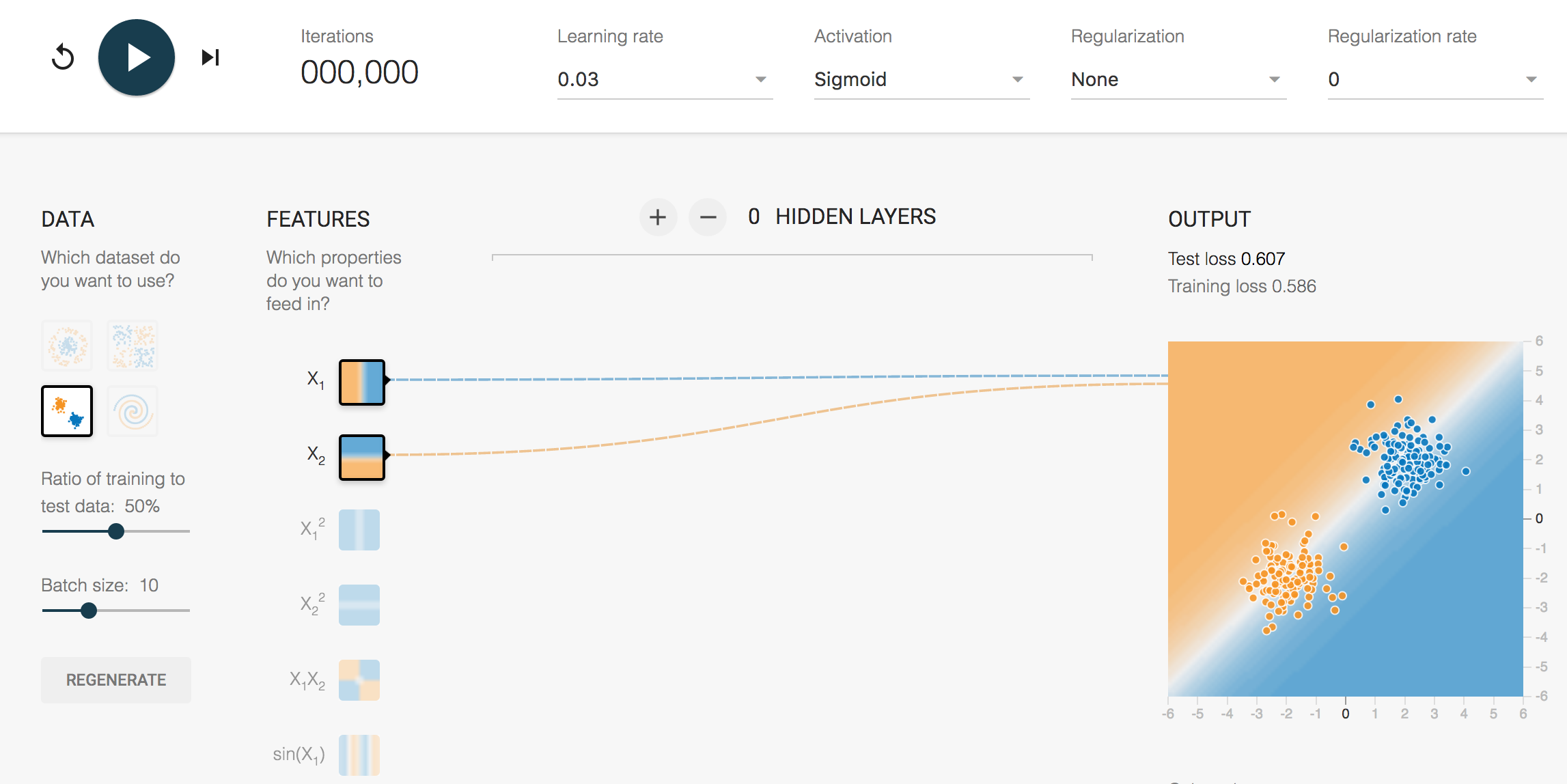
You can choose from four different datasets on the left side of the page in the DATA panel: Circle, Exclusive Or, Gaussian, and Spiral.The actual data point locations are available on the right side under the OUTPUT label. Do not change the ratio of training to test data or click the REGENERATE button throughout this question. Batch size indicates how many samples are used in your mini-batch gradient descent. You may change this parameter if you want.
The neural network model is in the middle of DATA and OUTPUT. This model is a standard ‘‘feed-forward" neural network, where you can vary: (1) the input features (2) the number of hidden layers (3) the number of neurons at each layer. By default, it uses only the raw inputs and as features, and no hidden layers. You will need to change theses attributes later.
Several hyper-parameters are tunable at the top of the page, such as the learning rate, the activation (nonlinearity) function of each neuron, the regularization norm as well as the regularization rate.
There are three buttons at the top left for you to control the training of a neural network: Reset, Run/Pause and Step (which steps through each mini-batch of samples at a time).
1. Hand-crafted Feature Engineering
Now that we are familiar with the Playground, we will start to build models to classify samples.
First you are going to earn some experience in hand-crafted feature engineering with a simple perceptron model with no hidden layers, sigmoid activations, no regularization. In other words, don’t change the model you’re given by default when loading the page.
A perceptron (single-layer artificial neural network) with a sigmoid activation function is
equivalent to logistic regression. As a linear model, it cannot fit some datasets like the Circle,
Spiral, and Exclusive Or. To extend linear models to represent nonlinear functions of , we can apply the linear model to a transformed input .
One option is to manually engineer . This can easily be done in the Playground since you are given 7 different features to choose from in the FEATURES panel.
Task: You are required to find the best perceptron models for the four datasets, Circle, Exclusive Or, Gaussian and Spiral by choosing different features. Try to select as few features as possible. For the best model of each dataset, you should report the selected features, iterations and test loss in a table. If you also change other hyper-parameters, e.g. the learning rate, you should include them in your report.
For each dataset (Circle, Exclusive Or, Gaussian and Spiral), please include a web page screenshot of the result in your report and explain why this configuration works.
(Note: Don’t worry if you cannot find a good perceptron for the Spiral dataset. For the other three datasets, the test loss of a good model should be lower than 0.001.)
2. Regularization
Forget the best features you have found in last question. You should now select all the possible (i.e. all 7) features to test the regularization effect here.
You are required to work on the three datasets: Circle, Exclusive Or and Gaussian.
Task A: Try both L1 and L2 regularization with different (non-zero) regularization rates. In the report, you are required to compare the decision boundary and the test loss over the three models trained with similar number of iterations: no regularization, L1 regularized, L2 regularized.
For each dataset (Circle, Exclusive Or and Gaussian), please include a web page screenshot of the result in your report and explain why this configuration works.
Task B: We have learned that L1 regularization is good for feature selection. Take a look at the features with significantly higher weights. Are they the same as the ones you select in last question? Write down the results you observe in your report. (You can get the feature weights by moving the mouse pointer over the dash lines.)
3. Automated Feature Engineering with Neural Network
While we were able to find different parameters which were able to make good predictions, the previous two sections required a lot of hand-engineering and regularization tweaking :( We will now explore the power of a neural network’s ability to automatically learn good features :) Let’s try it out on two datasets: the Circle and Exclusive Or.
Here we should only select and as features (since we are trying to automatically learn all other features from the network). As we have previously seen, a simple perceptron is not going to learn the correct boundaries since both datasets are not linearly separable. However, a more complex neural network should be able to learn an approximation of the complex features that we have selected in the previous experiments.
You can click the + button in the middle to add some hidden layers for the model.
There is a pair of + and - buttons at the top of each hidden layer for you to change the number of the hidden units. Note that each hidden unit, or neuron, is the same neuron from Lecture 17 (possibly varying the sigmoid activation function).
Task: Find a set of neural network model parameters which allow the model to find a boundary which correctly separates the testing samples. Report the test loss and iterations of the best model for each dataset. If you modify the other parameters (e.g. activation function), please report them too. Can it beat or approach the result of your hand-crafted feature engineering?
For each dataset (Circle, Exclusive Or), please include a web page screenshot of the result in your report and explain why the configuration would work.
4. Spiral Challenge (Extra credit)
Congratulations on your level up!
Task: Now try to find a model that achieves a test loss lower than 0.01 on the Spiral dataset. You‘re free to use other features in the input layer besides and , but a simpler model architecture is preferred. Report the input features, network architecture, hyper parameters, iterations and test loss in a table. For simplicity, please represent your network architecture by the hidden layers a-b-c-…, where a, b, c are number of hidden units of each layer respectively.
Please include a web page screenshot of the result in your report and explain why this configuration works.
You are now a neural network expert (on the Playground)!